A Lightweight, Modular n8n Pipeline for Automated Virtual Host Videos
Nov 28, 2025 · 2 min read
An experiment in script-driven video production: a modular n8n pipeline that turns a plain-text script into a lip-synced virtual host video in about three minutes on consumer-grade hardware.
TL;DR
- Goal: Build a script-driven video production flow. Use lightweight automation to turn text into avatar videos with lip-sync and a few basic expressions, keep the production cost in a manageable range, and leave room for a person to step in.
- Strategy: Use a CSV file as the script hub, with narration, character, background, and music managed separately. The whole flow is wired together in n8n, so every step can be swapped out or taken over by hand.
- Outcome: On an ordinary laptop, a short video takes roughly three minutes to generate and export. Once the flow is stable, content can be produced repeatedly at low cost, and a person can step in to fix things at any node.
Why I started this project
The motivation was straightforward. I wanted to turn the AI notes and technical understanding I build up over time into short videos I can produce steadily, instead of starting from scratch each time.
Fully automated video tools are convenient, but in practice it is easy to run into unstable content, details that drift, and post-production fixes that cost too much. So I narrowed the scope and fixed the format at 1.5 to 2 minutes, explaining a single concept clearly.
The benefit is that the whole flow can be broken into parts, and it is easier to turn into a repeatable system.

Design decisions
The overall video style stays simple and consistent. The point is not to build elaborate visuals, but to let the system run reliably over the long term.
The avatar character is set to be neutral and steady, with the number of expressions deliberately kept to a few core states. After testing, I found that more expressions actually increase generation errors and raise the maintenance cost.
The background and framing also use a fixed structure, so every video stays visually consistent and only varies in small details.

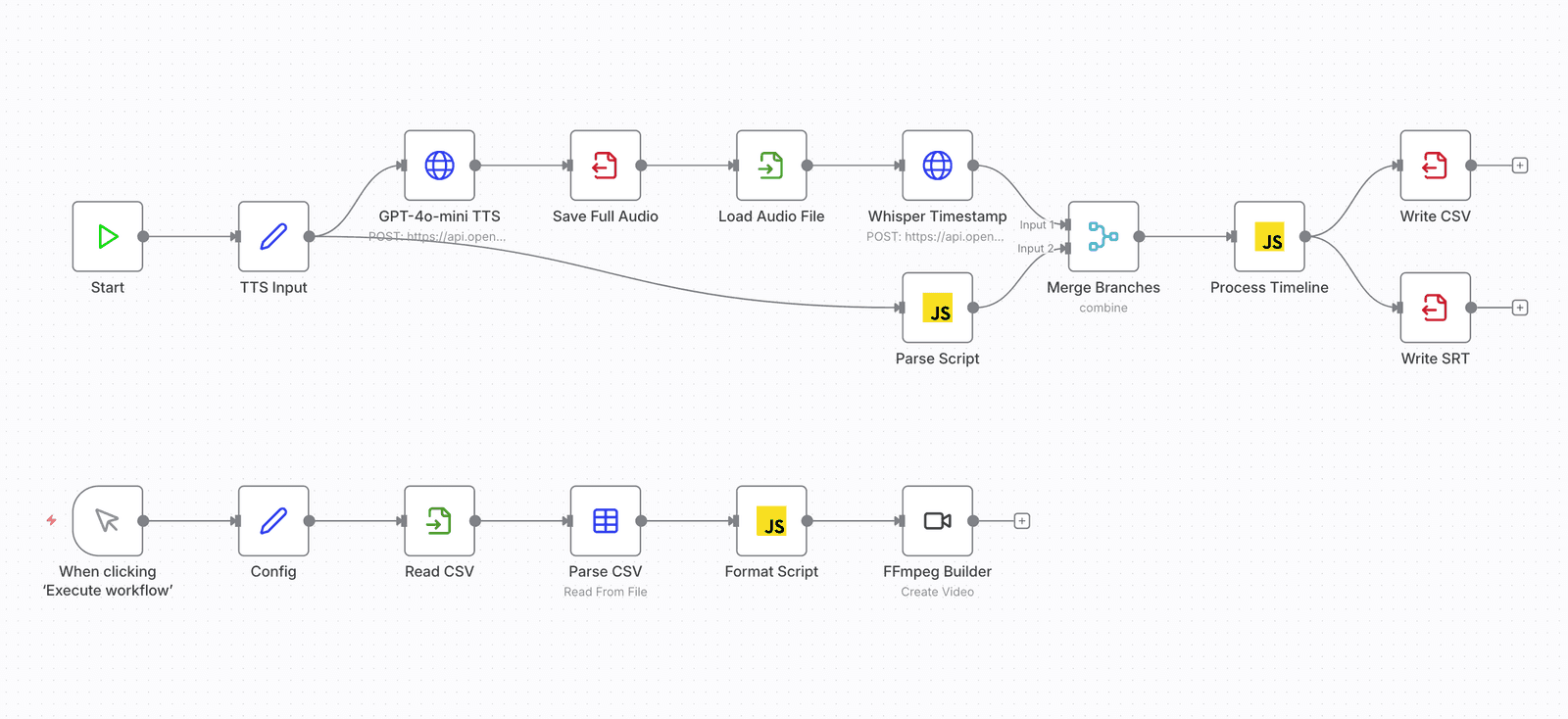
How the system runs
The whole flow is orchestrated in n8n. The core logic splits script → audio → time alignment → video output into a few independent nodes.
The flow goes roughly like this:
First, GPT-4o-mini TTS generates the narration audio.
Then Whisper produces word-level timestamps, so the audio can be mapped onto a timeline.
Next, a synchronization step written in Node.js turns the audio and timing information into usable timeline data.
Finally, FFmpeg handles the video compositing and export.
Throughout the flow, the CSV holds the script and metadata, so every step can be checked again or regenerated.
A human-in-the-loop design
One of the more important parts of this system is that it deliberately keeps room for a person to step in.
Every node can be swapped out or taken over by hand, for example:
- The narration can be replaced with a real voice recording.
- Illustrations can be designed by hand instead of generated with AI.
- The timeline can be corrected in spots and then fed back in.
The reason is to keep the flow flexible, rather than locking it entirely into automation.
In actual use, this hybrid flow turns out to be more stable, and it is easier to control both quality and cost.
Results
On an older, lower-spec laptop, the whole flow from text input to video output finishes in about three minutes.
Because TTS and Whisper are themselves cheap to run, the cost of testing and re-running the whole thing stays low too.
The clearer takeaway after running it is that once the flow is fixed, producing content becomes a repeatable piece of engineering rather than a creative act designed from scratch each time.

Next steps
This flow already produces short-video content reliably.
The next steps go in two directions:
The first is adding more variation in the visual layer, such as simple motion layers, key captions, or on-screen prompts.
The second is expanding the character's expressions and tone control, so the avatar can express itself with more nuance across different content.
The core, though, will not change. It will stay lightweight, modular, and open to manual handover.