用輕量模組化的 n8n Pipeline 自動產生虛擬主播影片
2025 年 11 月 28 日 · 閱讀時間 2 分鐘
一個用腳本驅動影片產製的實驗:用模組化的 n8n pipeline,在一般消費級硬體上,大約三分鐘內把純文字腳本轉成一支帶有口型同步的虛擬主播影片。
重點摘要
- 目標: 建立一套可以由腳本驅動的影片製作流程。用輕量自動化方式,把文字內容轉成具備口型同步與基礎表情的虛擬主播影片,讓製作成本保持在可控範圍,同時保留人工介入空間。
- 策略: 用 CSV 作為腳本中心,將旁白、角色、背景、音樂等內容拆開管理。整個流程以 n8n 串接不同節點,讓每個步驟都可以被替換或手動接管。
- 成果: 在一般筆電上,大約三分鐘可以完成一支短影片的生成與輸出。流程穩定後,可以持續用低成本方式反覆生成內容,也能在任意節點插入人工修正。
為什麼開始這個專案
一開始的動機很直接。我想把平常累積的 AI 筆記與技術理解,轉成可以穩定輸出的短影片,而不是每次都重新從零製作。
市面上的全自動影片生成工具雖然方便,但在實際使用時,很容易遇到內容不穩定、細節失控、後期修正成本過高的問題。因此我選擇把範圍縮小,固定在 1.5 到 2 分鐘的短內容,只講清楚一個概念。
這樣的好處是整個流程可以被拆解,也比較容易做成可重複的系統。

設計選擇
整體影片風格維持簡單一致的方向。重點不是做出複雜畫面,而是讓系統可以長期穩定運作。
虛擬主播角色設定偏中性、穩定,表情數量被刻意控制在少數幾種核心狀態。實際測試後發現,表情一多反而會增加生成錯誤,也會讓維護成本上升。
背景與鏡位也採用固定結構,讓每支影片在視覺上維持一致性,只在細節上做輕微變化。

系統運作方式
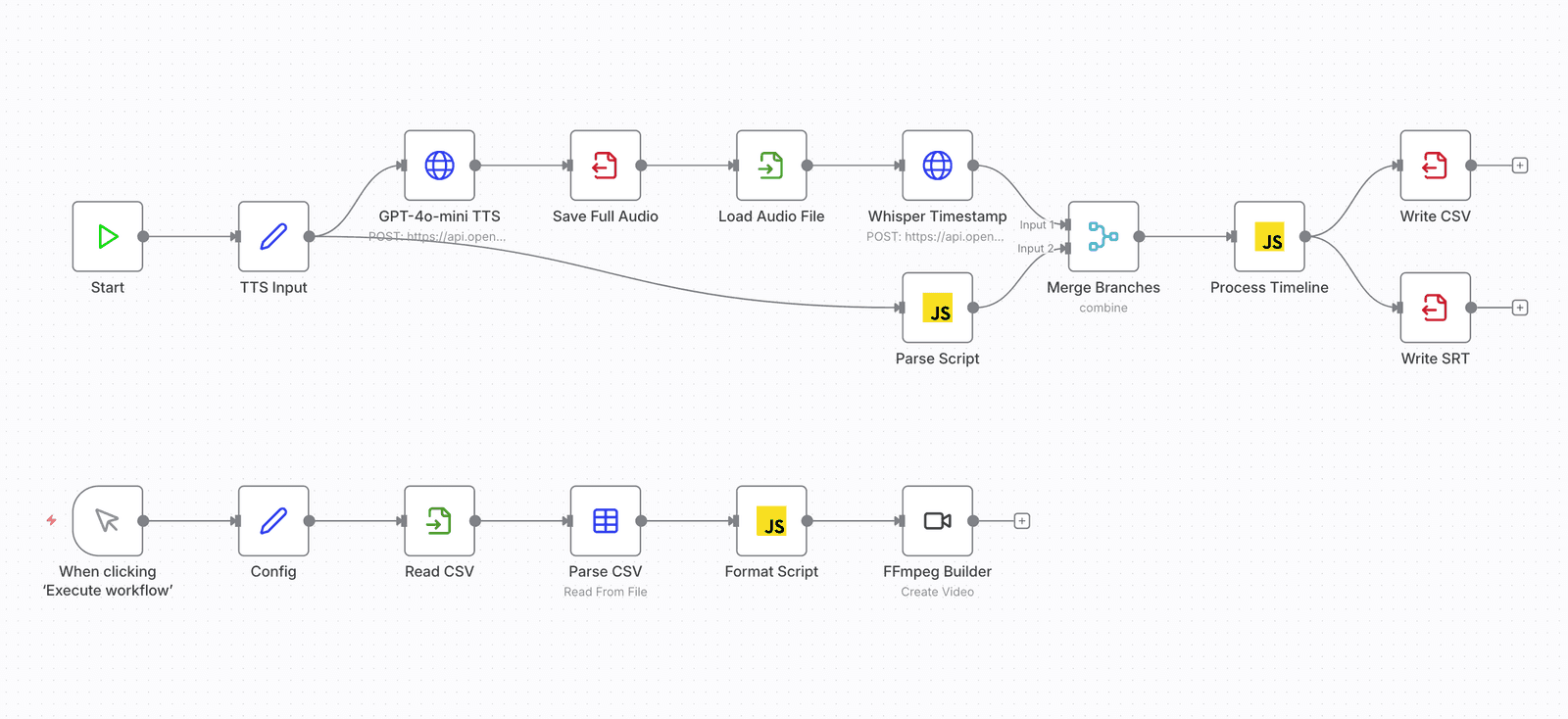
整個流程由 n8n 負責編排,核心邏輯是把「文字腳本 → 語音 → 時間對齊 → 影片輸出」拆成幾個獨立節點。
流程大致如下:
首先用 GPT-4o-mini TTS 生成旁白語音。
接著用 Whisper 產生逐字時間戳記,讓語音可以對應到時間軸。
然後透過 Node.js 寫的同步處理邏輯,把語音與時間資訊整理成可用的時間資料。
最後交給 FFmpeg 進行影片合成與輸出。
CSV 在這個流程中負責保存腳本與中繼資料,讓每一步都可以回頭檢查或重新生成。
人機共做的設計方式
這套系統一個比較重要的設計,是刻意保留人工介入的位置。
每一個節點都可以被替換或手動接手,例如:
- 旁白可以改成真人錄音
- 插圖可以不用 AI 生成,而是手動設計
- 時間軸可以局部修正後再回流
這樣做的原因是希望流程保持彈性,而不是完全被自動化綁死。
在實際使用上,這種混合式流程反而更穩定,也更容易控制品質與成本。
運行結果
在一台規格較舊的筆電上,整個流程從輸入文字到輸出影片,大約三分鐘內可以完成。
因為 TTS 和 Whisper 本身成本很低,所以整體測試與重跑的代價也不高。
實際運作後比較明顯的感受是,當流程固定之後,內容產出變成一種可重複的工程,而不是每次都重新設計的創作行為。

下一步與延伸
目前這套流程已經可以穩定產出短影音內容。
下一步會往兩個方向延伸:
第一是增加更多視覺層的變化,例如簡單的動態圖層、重點字卡或資訊提示。
第二是擴充角色表情與語氣控制,讓虛擬主播在不同內容中有更細緻的表達能力。
但整體核心不會改變,仍然會維持輕量、可拆解、可人工接管的結構。